
OCR is the use of technology to recognize the text characters from the handwritten, physical documents and any digital image of physical materials.
The essential thing about the OCR is it distinguish the characters from physical documents and translate them into code, and that can be used for data processing.
OCR also refers to text recognition.
Now if we talk about the OCR System, it contains hardware and software. In hardware, an optical scanner is used to scan the physical document and software works after the document scanned. Software typically handles the most advanced part of this process. Now artificial intelligence is also used to implement for more sophisticated and intelligent character recognition like languages identification and styles of handwriting.
The Process starts with the scanning of a hard copy of any legal, historical or any handwritten document. This document is converted into PDFs. Once it is saved in soft copy, this becomes editable with a word processor.
How optical character recognition works
This technology starts with its scanning part of a physical document. Once all pages are scanned OCR software converts the document into two-colour or black and white, version.
The scanned image or bitmap is analyzed, and dark and light areas are identified. Here dark areas are defined as characters and light areas are identified as background.
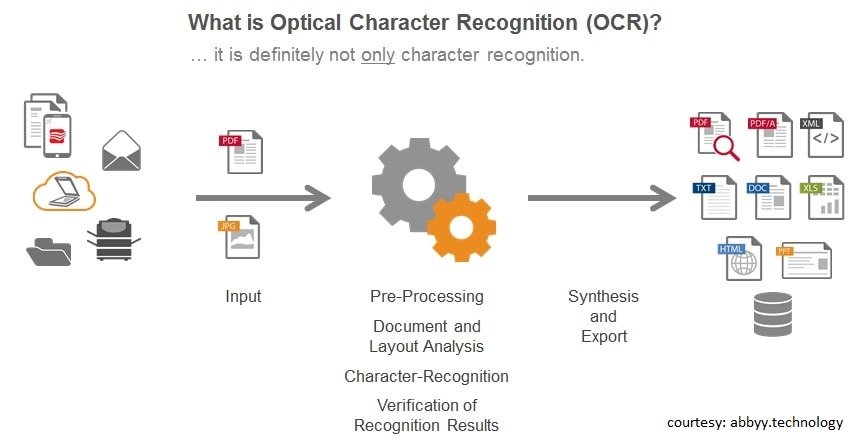
Now dark areas are further processed to find the alphabetic letter or numeric digits. OCR programs may vary in their technologies but involve targeting one character, word or block of text at a time. After identifying the characters, the program uses one of two algorithms:
A. Pattern Recognition:
Here OCR Programs are fed with different examples of text in various fonts and formats. It helps the programs to compare, and recognize and help to identify the characters in the scanned document.
B. Feature detection
In this type of algorithm, various rules are applied. As per the features of a specific letter or number to identify the characters in the document. Features may include the different shapes like the number of angles, lines, crossed lines or curves in character for comparison. In letter “H” two vertical lines and one horizontal line in between them in the middle.
When a character is identified, it is converted into an ASCII (American Standard Code for Information Interchange) code that can be utilized by computer systems to handle further manipulations. Now there are basic litter errors which can be correct by a user.
Now users can proofread and make sure no complexity in the document for future use.
OCR use cases
- In the Banking sector, any cheque can be accepted by an electronic machine and can save the cost and time of a bank teller
- It can be used by any search engine to index the printed document in its SERPs
- OCR can be used in scanning and printed documents into editable versions with processors like Google Docs or Microsoft Word
- Deciphering documents into text that can help visually impaired or blind people to read
- Automating data entry to process data in the electronic database
- Archiving historical information, such as library, newspapers, magazines or phonebooks into a format which can be search
- Placing signed legal documents in an electronic database
- Recognizing text of a vehicle number plates with this OCR System
- Translating words within an image into a specified language.
Benefits of Optical Character Recognition System are followings
- Save times
- Decreased errors
- Minimized effort
- Saving cost












Add comment